
I ran into som very strange problem on an SQL server this fall that I need to tell you about.
The Error
A read of the file ‘D:\SQL PATH\Data.mdf’ at offset 0x0000001ad60000 succeeded after failing 1 time(s) with error: incorrect pageid (expected 1:214336; actual 14854:3166640).
Even if we see these error SQL was able to repair them by it self.
Backround
Running esxi 7.0.3
Running fiberchannel
Running nvme storage
Soloution for me
Replace bad HBA on vmware host
When these kind of errors occurs in the SQL database, TAKE IT SERIOUSLY.
If you Google this error message everything points to hardware issue.
But in this case I did not find any errors on the switch, vmware or storage. The only thing is this error message from SQL.
It seems like an error like this can sneak up on you. Finally we got a “real” krash, then we was able to see error in what I explain below.
Here are some troubleshooting tips and tricks for you.
First of all, find the baseline. The errors can be old so you need to now the values from today and if they change. Or you can reset everything and start from 0. But you need to know if the error that we are looking at ar increasing or not.
How to see these error from ESXi point of view
ssh to the host
Run this command:
esxcli storage san fc stats get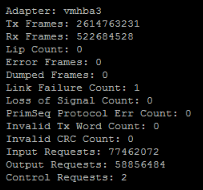
Of course the can be some numbers here, reboot, upgrade a switch can cause errors. But do they change when the system is running normal.
Sanwtich
To clear stats on brocade switch
statsclearslotstatsclearTo see errors on the specific port
portsstatsshow 13
The er_somthing schoud be 0, if you see some numbers on er_bad_os or er_tx_c3_timeout then we have an issue.

To see all ports at the same time. 0 is ok and the error tables schould be 0. If you reboot a host or upgrade something in the chain there will be errors in the tables below. So baseline your numbers.
porterrorshow
How can we see if something else is happening on the switch, such as load on the port and so on.
mapsdb --show
So final thought around this.
- Take SQL errors seriously
- Methodical troubleshooting
- Find a baseline for the error numbers
- Change host
- Reboot host
That was all for today!
Keep hacking!
//Roger

Leave a comment